Recent advancements in real-time neural rendering using point-based techniques have paved the way for the
widespread adoption of 3D representations. However, foundational approaches like 3D Gaussian Splatting
come with
a substantial storage overhead caused by growing the SfM points to millions, often demanding
gigabyte-level disk
space for a single unbounded scene, posing significant scalability challenges and hindering the splatting
efficiency.
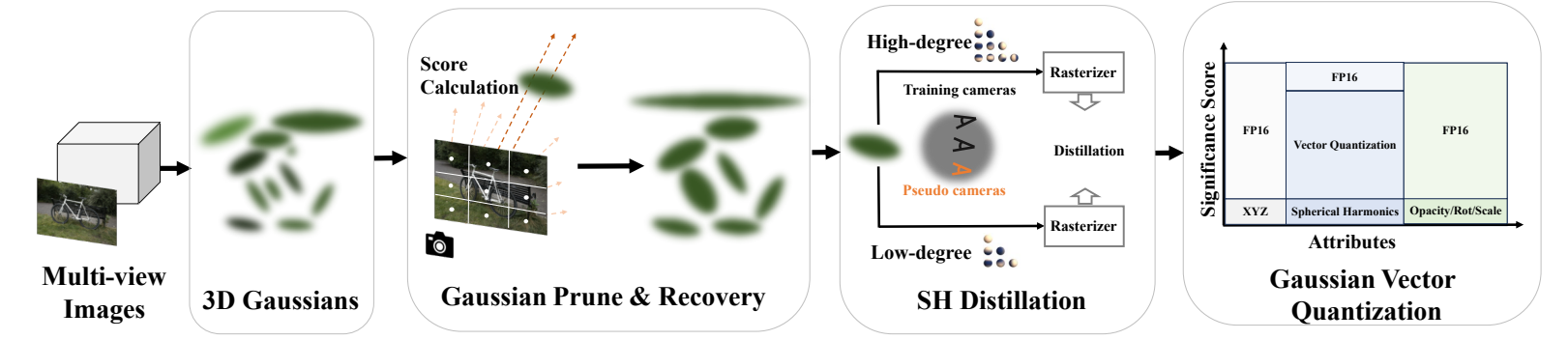
To address this challenge, we introduce LightGaussian, a novel method designed to transform 3D Gaussians
into
a more efficient and compact format. Drawing inspiration from the concept of Network Pruning,
LightGaussian
identifies Gaussians that are insignificant in contributing to the scene reconstruction and adopts a
pruning and
recovery process, effectively reducing redundancy in Gaussian counts while preserving visual effects.
Additionally,
LightGaussian employs distillation and pseudo-view augmentation to distill spherical harmonics to a lower
degree,
allowing knowledge transfer to more compact representations while maintaining scene appearance. Furthermore, we
propose
a hybrid scheme, VecTree Quantization, to quantize all attributes, resulting in lower bitwidth
representations with minimal accuracy losses.
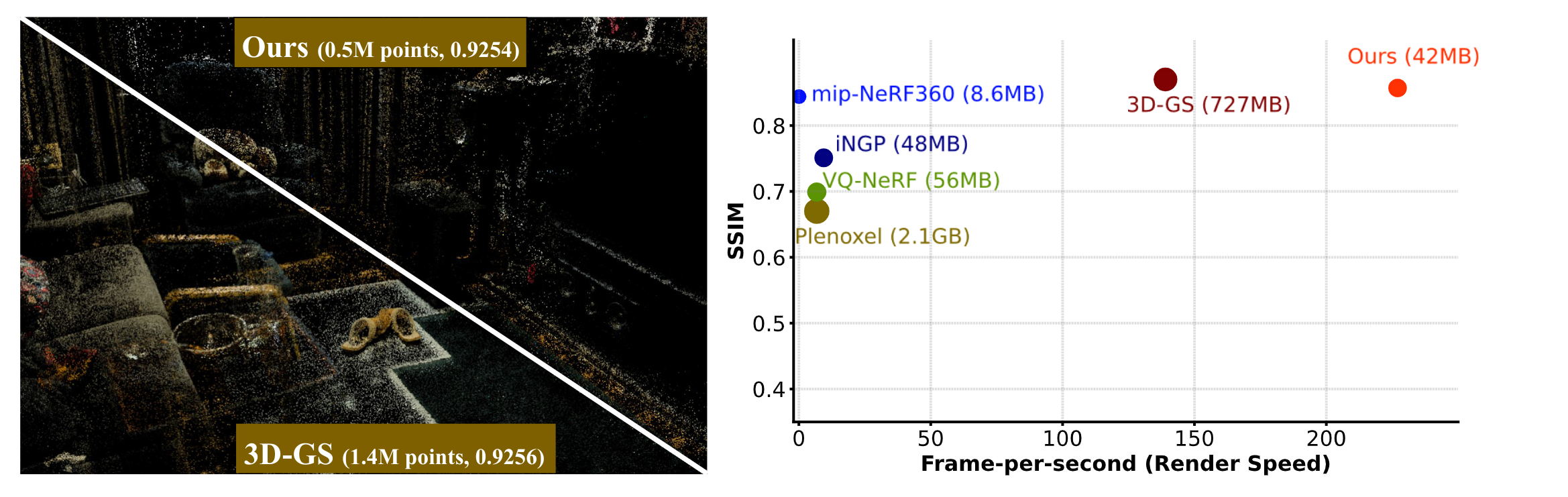
In summary, LightGaussian achieves an averaged compression rate over 15× while boosting the FPS from 139
to 215,
enabling an efficient representation of complex scenes on Mip-NeRF 360, Tank & Temple datasets.